🔁 Steps to Create a Branch in Databricks, Pull from Git, and Merge into a Collaborative Branch
-
Create a New Branch in Databricks:
-
Go to the Repos tab in your workspace.
-
Navigate to the Git-linked repo.
-
Click the Git icon (or three dots ⋮) and choose "Create Branch."
-
Give your branch a name (e.g.,
feature-xyz) and confirm.
-
-
Pull the Latest Changes from Git:
-
With your new branch selected, click the Git icon again.
-
Select “Pull” to bring the latest updates from the remote repository into your local Databricks environment.
-
-
Make Changes & Commit:
-
Edit notebooks or files as needed in your branch.
-
Use the "Commit & Push" option to push changes to the remote repo.
-
-
Merge into the Collaborative Branch:
-
Switch to the collaborative branch (e.g.,
devormain) in Git or from the Databricks UI. -
Click "Pull & Merge".
-
Choose the branch you want to merge into the collaborative branch.
-
Review the changes and confirm the merge.
-
✅ Best Practices:
-
Always pull the latest changes before merging to avoid conflicts.
-
Communicate with teammates before merging into a shared branch.
-
If working with GitHub/GitLab, you can also create a Pull Request (PR) for code review before merging.


it's showing all of the changes (version)that applied to the notebook.

we can able to restore the version of click the restore the version

Github --> Microsoft
Gitlab --> GitLab is a web-based DevOps platform that provides a Git repository manager with features like version control, CI/CD (Continuous Integration/Continuous Deployment), issue tracking, code review, and more — all in one place.
It’s built on top of Git, so it supports distributed version control, but adds many tools around it to support the entire software development lifecycle (SDLC).
It's for Azure.





It following window appears to authorize the databricks to connect .

after clicking authorize the its shows the message as link was succesfull.

To verify, go under linked accounts, we can see the GitHub account there.
Navigate to the Workspace section and go to your Home folder. Under the folder structure, click on the Repos tab.
You will see the email address associated with the Azure or GitHub account used for integration. Click on that account.
In the top-right corner, click the "Create Git Folder (Recommended)" button. This will create a Git-enabled folder linked to your repository, allowing you to version control your notebooks and collaborate more effectively.




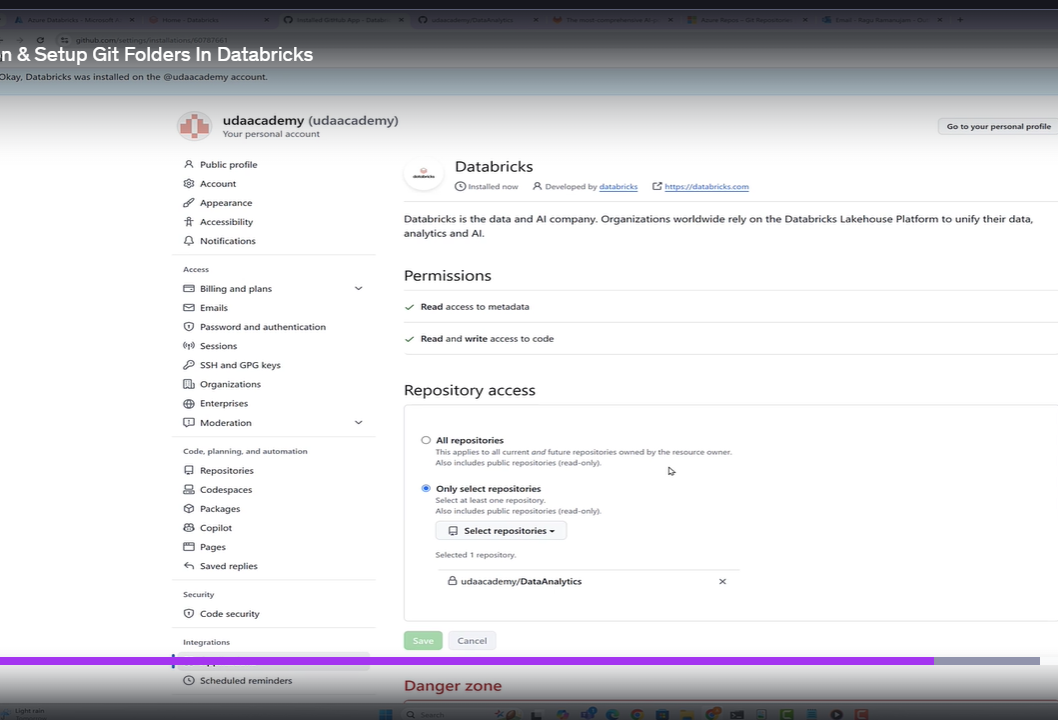
If we find any issues , click on the confire git option its takes you to the next git hub page select the particular repo and click install databricks and then go side and give access to the repository.

we have create Git repository folder .



Over there we can be able to create a new branch under the main branch.




We just created the notebook under the branch in the databricks, now we have to push the folder into the git repository.


Then go to GitHub, there we can either push it via the pull request tab or go inside the branch where the commit was made, where we can see the option compare and pull.










✅ Steps for Merging Code into a Collaborative Branch
-
Switch to the Collaborative Branch:
Make sure you’re on the branch where collaboration is happening.
-
Pull the Latest Changes (Optional but Recommended):
Ensures your local branch is up to date before merging.
-
Merge Your Feature or Working Branch:
This merges the changes from your feature branch into the collaborative branch.
-
Resolve Any Merge Conflicts (If Any):
If Git reports conflicts, you'll need to manually edit the conflicting files, then:
-
Push the Updated Collaborative Branch:
Pushes the merged changes to the remote repository so other team members can see them.
📝 Example Use Case:
Let’s say multiple developers are working on the same project:
-
Each developer works on a separate feature branch.
-
They regularly merge their changes into a shared collaborative branch (like
devorqa). -
Once stable, the collaborative branch is merged into
mainfor release.
Comments
Post a Comment